

SSD基本的组成结构有Flash颗粒和Flash控制器,Flash控制器有芯片,负责Flash的读写、磨损均衡、寿命监控等。近日,PMC的首席架构师张冬在中国闪存峰会的分论坛上分享了名为“浅谈”闪存控制器架构的主题演讲。
控制器主要做的就是这么几件事情:
第一,后端访问Flash,管理后端Flash颗粒,包括各种参数控制和数据IO。控制器需要把从前端发过来的IO翻译成Flash的指令格式。其实,不同厂商采用的协议不一致,后端要做的是适配不同的厂商提供颗粒的参数,虽然大家遵循的协议一样,但一些机密参数厂商不对外透露,而有了这些参数后可以更快更好地在Flash芯片中进行读写。
第二,前端提供接口和协议。实现对应的SAS/SATA target协议端或者NVMe协议端,获取Host发出的IO指令并解码和生成内部私有数据结果等待执行。跟主机驱动,跟上面的协议栈,利用标准格式输配到系统里面,接收主机端发过来的指令,这两个还不是核心的层次。
第三,最核心的是FTL层。指令接收过来以后,部件里面怎么处理指令。包括影射,元数据、元数据保存,磨损均衡等一堆东西都需要处理,所以这块是各个厂商竞争力的体现。它是最重要的,这块是第二重要的,这块反而最不重要,因为这块是标准化的。
后端都有哪些操作内容:
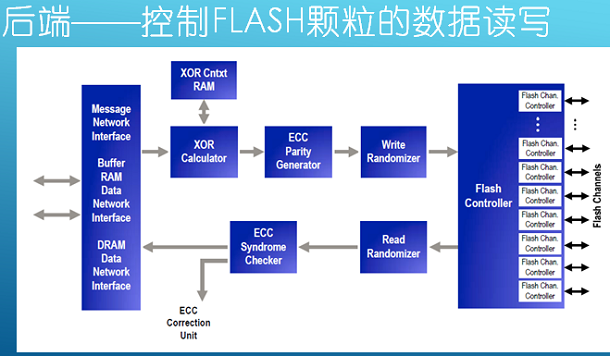
第一,闪存通道控制器,每个控制器里有多个通道,每个通道下有多片Flash,一个通道挂8片,需要有一个信号选择8片,每次发一个信号下去,要读哪一片,要告诉他,有一个片选。通道数量不同厂商的产品都不一样,高端的有的16通道、32通道,有的8通道、1通道。它跟后端Flash颗粒有托管协议。
数据写到Flash的时候要做两个事情:一个是做ECC校验,Flash靠电压检测来表示。加一个比较电压检测,因为这个过程容易出错,比如说用1.2伏表示零,1.3伏表示1,如果检测出来是1.25伏怎么办?你是0还是1,因为出错率非常高,所以需要ECC。
ECC是通用的称谓,包括好几种算法,纠错率较低的BCH算法,还有LABC低密度校验法,我们用更少的位校验更多的错误。高密度是说,我不在乎校验位的容量,最高的就是RAID1,有一份数据复制一份,那个错了,这个还在,那个成本太高了。4K我有多少ECC。LBAC是业内最低密度的校验,已经达到理论的极限了。这个东西做起来的话,用CPU算的话,这个速度太慢了。数据进来以后,一个数据或者两个数据输出。Flash是拿晶体管(音译),你要往里写相同数据的时候,我都充电,可能就产生干扰,这时候出错率就增加了,把原始数据,可能有多个零,一万个零,写进去的时候,会用一个多项式重新算一遍,最后产生的数据,一个0,一个1,这样就不会导致相邻的cell同时充电,出错率降低,读出来的时候也要经过它,把原始数据重新算过来,写到DARM里面,所以需要两步操作。读的时候扰码,加扰,解扰,看ECC有没有错误,有错纠错,然后把芯片发到内部,供后续的程序处理。算RAID的话,多个颗粒之间做RAID的话用云加速计算器去算。
前端基本上没有什么大家都是一样的,如果你遵从NVMe标准的话,包括提交命令、完成命令这些东西都定好了,这个数量可以达到64K个,同一时刻,系统里面可能存在64K×64K IO排着,但是系统用不到这么多Queue,因为底下的介质达不到64K。设计的时候,永远不可能达到,本身就是错误的,肯定会达到,因为底层的科技的进步是没有办法想象的。
一般来讲,现在的产品,一般做硬件的时候,比如说做64 Queue,但是这些Queue都是主机内部里的,Flash控制器里面需要对每个Queue有一个对应的接受的窗口,这个是硬件计算机,然后会把地址写到控制器里面,这时候控制器知道从主机内存哪个位置把命令拿过来,控制器是从主机里面拿命令,不是主机发送给控制器。NVMe 1.2的标准里面做了改变,主机直接把命令扔到控制器少了一步操作。支撑NVMe的控制器不仅仅是软件的改动,硬件也需要改动,你可以拿纯软件模拟,这样的话就非常慢了,你需要有硬件计算器在里面。至于指令解码这块都是软件,这块没有硬件,这块做硬解码不太划算,基本上拿CPU,把命令接收进来,跑代码算一下。
第三,核心层FTL层:这个是关键竞争力所在,纯软件算法,元数据管理,数据布局影射、磨损均衡、垃圾回收、缓存策略,发了IO下来,Flash写了,你发一笔下来,我等等,后面可能有一万笔,我把4K放到缓存里面,一万笔就不用下来了,我就可以降低写放大。如果一个颗粒坏了,我也可以算出来。掉电元数据一致性保障,这个也是体现竞争力的地方。之前的产了掉电以后再开机,因为卡还没有准备好,一直等卡把元数据恢复出来,重新恢复一致性才了进去。最夸张的可能到八九十都有可能,启动一台机器掉电半小时,现在的新产品,基本上就是10秒,或者几秒钟。
这个算法也不是纯软件的,当然也有硬加速的成分在里面,这个就看你用谁家的芯片。有的芯片支持硬加速的东西,比如说链表的恢复。因为做垃圾回收的时候要用到链表,拿传统的软件算法,插入一个链表或者追加一些项目的话,耗费的周期是非常大的,这个时候用硬加速并行起来,再加上一些硬逻辑的加速的话,这块开销是可以省下来了,省下来以后,IO时延就降下来了。Flash时延很重要,每增加一小步都会影响时延,最好是直接到Flash颗粒,什么都不加,但是这样就没办法用,没有办法管理Flash了。
以上说的是一款Flash控制器要做的事情。做这些事情有各种各样的方法,各种各样的架构设计。稍微总结一下。
Flash控制器的两种策略和方式:
一种是少量的强核心 少量硬件加速。所谓强核心就是一个核心的性能非常高,频率也高,里面的器件也多,分支预判、并行度、数量、执行管道,各种参数都往上标,这就所谓的强核心。核心强了以后,硬加速就不需要这么多了,可以用少量的硬加速。
另一种是大量弱核心 大量硬加速。比如说16个核心,每个核心比较弱,但是能够增加执行的并行度,我有16个并发核心执行,我们跑16套处理程序,这是两种架构。
多核心的两种协作方式:
多核心的协作有同构协作和异构协作两种方式。
同构协作就是每个核心做的事都是完全一样的,处理的步骤完全一样。如果你的控制器阵列里面有16个IO,有16个核心,每个核心都能处理一个IO,这是同构协作,每笔IO处理的时候,都有步骤,先指令、解码,形成对应的操作,下一步算RAID,带入到表里面,查一下我哪些地方是空的可以写,再就是找一下影射表之类的,再就是发送给后端Flash控制器,然后写下去,一步一步执行,每一个核都可以做这个事情,这个是同构协作。
异构协作就是多个核心做不同的事情。处理同一个IO,第一个IO第一步,第一个核心处理,这个核心处理完以后,把这个IO扔到下一个核心,再处理下一步,我这个核心空出来以后,我处理下一个IO的第一步,这就是所谓的流水线了,异构就是这样的。这叫大量重核心,关于它的两种协作,我之前写过文章,在公众号里面,大家可以看一下。
以PMC产品示例介绍控制器的架构:
首先它有一个网络,网络承载16个CPU核心,每个核心里面有一个类似于网卡的控制器,网卡连到网络上,说白了网络就是4口路由器或者交换机连起来的网络,多个CPU之间连起来,此外还有硬加速模块。
这里有以下几部分:
RAM控制器,因为芯片上需要有一定量的RAM放临时数据,写放大,读出来写进去,都要走RAM,
然后是PCIe控制器,这个跟前端PCIe对等的控制器,从这儿接收过来VM1。
后端Flash控制器,连Flash颗粒,通过一定数量的通道。
再就是加速器:
包括缓冲加速器,这个就是分8份,因为每做一个操作,都需要有相应的内存,把数据拷到内存里面,内存的维护很费时费力。比如说之前在X86装Linux,有很多的计算量。对于闪存,精打细算,必须把性能做到极致,这块用硬加速;
链表加速器,刚才已经提到了,哪块空着,哪块被应用,这块用软件维护很费力,(所以需要在这里作加速);
XOR加速器,XOR要用硬加速,当然还有外围辅助,串口等各种其他的控制器,图中没有具体显示。
所有模块通过一个网络互传数据,达到高度并行的目的,所以这个网络速度非常快。
软件的并行度。16个核心,我们提供的参考的部件,SSD厂商把自己优化的东西放进去开发出自己的部件,这几种基本上包含这样一些程序:因为每个IO读的地址可能有重叠,所欲需要有一个锁定协调;有管命令解析的,有管启动的,最核心是:有管日志的,有管磨损均衡的,有管查表的,有关写数据的,还有引擎对应的举动都在这儿,管前端的PCIe 管理员,初始化的配置,需要由它处理,data manager,这是主程序,分析干什么,生成一堆的后续步骤下发下去。其实每一块都可以跑在一个核心上,同一个角色可以复制多份,充分变小。16个核心,达到16份程序并行的运行,16个流水线的Stage,这样就可以屏蔽处理过程中的时延。







